Guardar y deployar un modelo predictivo
Contenido
Guardar y deployar un modelo predictivo¶
Para este ejemplo utilizaremos un árbol de decisión
import os
import pandas as pd
from xgboost.sklearn import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix, precision_score, recall_score, f1_score
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
Input In [1], in <module>
1 import os
2 import pandas as pd
----> 3 from xgboost.sklearn import XGBClassifier
4 from sklearn.model_selection import train_test_split
5 from sklearn.metrics import accuracy_score, confusion_matrix, precision_score, recall_score, f1_score
ModuleNotFoundError: No module named 'xgboost'
df = pd.read_csv(os.path.join('../Datasets/diabetes.csv'))
df.head()
| Pregnancies | Glucose | BloodPressure | SkinThickness | Insulin | BMI | DiabetesPedigreeFunction | Age | Outcome | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 148 | 72 | 35 | 0 | 33.6 | 0.627 | 50 | 1 |
| 1 | 1 | 85 | 66 | 29 | 0 | 26.6 | 0.351 | 31 | 0 |
| 2 | 8 | 183 | 64 | 0 | 0 | 23.3 | 0.672 | 32 | 1 |
| 3 | 1 | 89 | 66 | 23 | 94 | 28.1 | 0.167 | 21 | 0 |
| 4 | 0 | 137 | 40 | 35 | 168 | 43.1 | 2.288 | 33 | 1 |
feature_cols = ['Pregnancies', 'Insulin', 'BMI', 'Age','Glucose','BloodPressure','DiabetesPedigreeFunction']
X = df[feature_cols]
Y = df['Outcome']
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=1) # 70% training, 30% test
Optimización de parámetros¶
#https://github.com/conda-forge/hyperopt-feedstock
from hyperopt import fmin, tpe, hp, STATUS_OK,Trials
space ={
'n_estimators':hp.quniform('n_estimators',100,1000,1),
'learning_rate':hp.quniform('learning_rate',0.025,0.5,0.025),
'max_depth':hp.quniform('max_depth',1,13,1),
'subsample': hp.quniform('subsample',0.5,1,0.05),
'colsample_bytree':hp.quniform('colsample_bytree',0.5,1,0.05),
'nthread':6,
'silent':1
}
def objective(params):
params['n_estimators'] = int(params['n_estimators'])
params['max_depth'] = int(params['max_depth'])
classifier = XGBClassifier(**params)
classifier.fit(X_train,Y_train)
accuracy = accuracy_score(Y_test, classifier.predict(X_test))
return {'loss': 1-accuracy, 'status': STATUS_OK}
trials=Trials()
best=fmin(objective,space,algo=tpe.suggest,trials=trials,max_evals=20)
[17:15:14] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:576:
Parameters: { "silent" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
[17:15:14] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:1115: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
0%| | 0/20 [00:00<?, ?trial/s, best loss=?]
/usr/local/lib/python3.9/site-packages/xgboost/sklearn.py:1224: UserWarning: The use of label encoder in XGBClassifier is deprecated and will be removed in a future release. To remove this warning, do the following: 1) Pass option use_label_encoder=False when constructing XGBClassifier object; and 2) Encode your labels (y) as integers starting with 0, i.e. 0, 1, 2, ..., [num_class - 1].
warnings.warn(label_encoder_deprecation_msg, UserWarning)
/usr/local/lib/python3.9/site-packages/xgboost/data.py:262: FutureWarning: pandas.Int64Index is deprecated and will be removed from pandas in a future version. Use pandas.Index with the appropriate dtype instead.
elif isinstance(data.columns, (pd.Int64Index, pd.RangeIndex)):
[17:15:15] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:576:
Parameters: { "silent" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
[17:15:15] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:1115: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
5%|▌ | 1/20 [00:00<00:06, 3.09trial/s, best loss: 0.22510822510822515]
/usr/local/lib/python3.9/site-packages/xgboost/sklearn.py:1224: UserWarning: The use of label encoder in XGBClassifier is deprecated and will be removed in a future release. To remove this warning, do the following: 1) Pass option use_label_encoder=False when constructing XGBClassifier object; and 2) Encode your labels (y) as integers starting with 0, i.e. 0, 1, 2, ..., [num_class - 1].
warnings.warn(label_encoder_deprecation_msg, UserWarning)
/usr/local/lib/python3.9/site-packages/xgboost/data.py:262: FutureWarning: pandas.Int64Index is deprecated and will be removed from pandas in a future version. Use pandas.Index with the appropriate dtype instead.
elif isinstance(data.columns, (pd.Int64Index, pd.RangeIndex)):
[17:15:15] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:576:
Parameters: { "silent" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
[17:15:15] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:1115: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
10%|█ | 2/20 [00:00<00:07, 2.53trial/s, best loss: 0.22510822510822515]
/usr/local/lib/python3.9/site-packages/xgboost/sklearn.py:1224: UserWarning: The use of label encoder in XGBClassifier is deprecated and will be removed in a future release. To remove this warning, do the following: 1) Pass option use_label_encoder=False when constructing XGBClassifier object; and 2) Encode your labels (y) as integers starting with 0, i.e. 0, 1, 2, ..., [num_class - 1].
warnings.warn(label_encoder_deprecation_msg, UserWarning)
/usr/local/lib/python3.9/site-packages/xgboost/data.py:262: FutureWarning: pandas.Int64Index is deprecated and will be removed from pandas in a future version. Use pandas.Index with the appropriate dtype instead.
elif isinstance(data.columns, (pd.Int64Index, pd.RangeIndex)):
[17:15:16] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:576:
Parameters: { "silent" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
[17:15:16] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:1115: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
15%|█▌ | 3/20 [00:01<00:06, 2.45trial/s, best loss: 0.22510822510822515]
/usr/local/lib/python3.9/site-packages/xgboost/sklearn.py:1224: UserWarning: The use of label encoder in XGBClassifier is deprecated and will be removed in a future release. To remove this warning, do the following: 1) Pass option use_label_encoder=False when constructing XGBClassifier object; and 2) Encode your labels (y) as integers starting with 0, i.e. 0, 1, 2, ..., [num_class - 1].
warnings.warn(label_encoder_deprecation_msg, UserWarning)
/usr/local/lib/python3.9/site-packages/xgboost/data.py:262: FutureWarning: pandas.Int64Index is deprecated and will be removed from pandas in a future version. Use pandas.Index with the appropriate dtype instead.
elif isinstance(data.columns, (pd.Int64Index, pd.RangeIndex)):
[17:15:16] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:576:
Parameters: { "silent" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
[17:15:16] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:1115: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
20%|██ | 4/20 [00:01<00:06, 2.53trial/s, best loss: 0.22510822510822515]
/usr/local/lib/python3.9/site-packages/xgboost/sklearn.py:1224: UserWarning: The use of label encoder in XGBClassifier is deprecated and will be removed in a future release. To remove this warning, do the following: 1) Pass option use_label_encoder=False when constructing XGBClassifier object; and 2) Encode your labels (y) as integers starting with 0, i.e. 0, 1, 2, ..., [num_class - 1].
warnings.warn(label_encoder_deprecation_msg, UserWarning)
/usr/local/lib/python3.9/site-packages/xgboost/data.py:262: FutureWarning: pandas.Int64Index is deprecated and will be removed from pandas in a future version. Use pandas.Index with the appropriate dtype instead.
elif isinstance(data.columns, (pd.Int64Index, pd.RangeIndex)):
[17:15:16] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:576:
Parameters: { "silent" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
[17:15:16] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:1115: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
30%|███ | 6/20 [00:02<00:04, 2.90trial/s, best loss: 0.22510822510822515]
/usr/local/lib/python3.9/site-packages/xgboost/sklearn.py:1224: UserWarning: The use of label encoder in XGBClassifier is deprecated and will be removed in a future release. To remove this warning, do the following: 1) Pass option use_label_encoder=False when constructing XGBClassifier object; and 2) Encode your labels (y) as integers starting with 0, i.e. 0, 1, 2, ..., [num_class - 1].
warnings.warn(label_encoder_deprecation_msg, UserWarning)
/usr/local/lib/python3.9/site-packages/xgboost/data.py:262: FutureWarning: pandas.Int64Index is deprecated and will be removed from pandas in a future version. Use pandas.Index with the appropriate dtype instead.
elif isinstance(data.columns, (pd.Int64Index, pd.RangeIndex)):
/usr/local/lib/python3.9/site-packages/xgboost/sklearn.py:1224: UserWarning: The use of label encoder in XGBClassifier is deprecated and will be removed in a future release. To remove this warning, do the following: 1) Pass option use_label_encoder=False when constructing XGBClassifier object; and 2) Encode your labels (y) as integers starting with 0, i.e. 0, 1, 2, ..., [num_class - 1].
warnings.warn(label_encoder_deprecation_msg, UserWarning)
/usr/local/lib/python3.9/site-packages/xgboost/data.py:262: FutureWarning: pandas.Int64Index is deprecated and will be removed from pandas in a future version. Use pandas.Index with the appropriate dtype instead.
elif isinstance(data.columns, (pd.Int64Index, pd.RangeIndex)):
[17:15:17] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:576:
Parameters: { "silent" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
[17:15:17] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:1115: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
[17:15:17] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:576:
Parameters: { "silent" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
[17:15:17] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:1115: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
35%|███▌ | 7/20 [00:02<00:04, 2.95trial/s, best loss: 0.22510822510822515]
/usr/local/lib/python3.9/site-packages/xgboost/sklearn.py:1224: UserWarning: The use of label encoder in XGBClassifier is deprecated and will be removed in a future release. To remove this warning, do the following: 1) Pass option use_label_encoder=False when constructing XGBClassifier object; and 2) Encode your labels (y) as integers starting with 0, i.e. 0, 1, 2, ..., [num_class - 1].
warnings.warn(label_encoder_deprecation_msg, UserWarning)
/usr/local/lib/python3.9/site-packages/xgboost/data.py:262: FutureWarning: pandas.Int64Index is deprecated and will be removed from pandas in a future version. Use pandas.Index with the appropriate dtype instead.
elif isinstance(data.columns, (pd.Int64Index, pd.RangeIndex)):
[17:15:17] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:576:
Parameters: { "silent" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
[17:15:17] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:1115: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
40%|████ | 8/20 [00:03<00:04, 2.55trial/s, best loss: 0.22510822510822515]
/usr/local/lib/python3.9/site-packages/xgboost/sklearn.py:1224: UserWarning: The use of label encoder in XGBClassifier is deprecated and will be removed in a future release. To remove this warning, do the following: 1) Pass option use_label_encoder=False when constructing XGBClassifier object; and 2) Encode your labels (y) as integers starting with 0, i.e. 0, 1, 2, ..., [num_class - 1].
warnings.warn(label_encoder_deprecation_msg, UserWarning)
/usr/local/lib/python3.9/site-packages/xgboost/data.py:262: FutureWarning: pandas.Int64Index is deprecated and will be removed from pandas in a future version. Use pandas.Index with the appropriate dtype instead.
elif isinstance(data.columns, (pd.Int64Index, pd.RangeIndex)):
[17:15:18] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:576:
Parameters: { "silent" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
[17:15:18] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:1115: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
50%|█████ | 10/20 [00:03<00:03, 3.18trial/s, best loss: 0.22510822510822515]
/usr/local/lib/python3.9/site-packages/xgboost/sklearn.py:1224: UserWarning: The use of label encoder in XGBClassifier is deprecated and will be removed in a future release. To remove this warning, do the following: 1) Pass option use_label_encoder=False when constructing XGBClassifier object; and 2) Encode your labels (y) as integers starting with 0, i.e. 0, 1, 2, ..., [num_class - 1].
warnings.warn(label_encoder_deprecation_msg, UserWarning)
/usr/local/lib/python3.9/site-packages/xgboost/data.py:262: FutureWarning: pandas.Int64Index is deprecated and will be removed from pandas in a future version. Use pandas.Index with the appropriate dtype instead.
elif isinstance(data.columns, (pd.Int64Index, pd.RangeIndex)):
[17:15:18] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:576:
Parameters: { "silent" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
[17:15:18] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:1115: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
50%|█████ | 10/20 [00:03<00:03, 3.18trial/s, best loss: 0.22510822510822515]
/usr/local/lib/python3.9/site-packages/xgboost/sklearn.py:1224: UserWarning: The use of label encoder in XGBClassifier is deprecated and will be removed in a future release. To remove this warning, do the following: 1) Pass option use_label_encoder=False when constructing XGBClassifier object; and 2) Encode your labels (y) as integers starting with 0, i.e. 0, 1, 2, ..., [num_class - 1].
warnings.warn(label_encoder_deprecation_msg, UserWarning)
/usr/local/lib/python3.9/site-packages/xgboost/data.py:262: FutureWarning: pandas.Int64Index is deprecated and will be removed from pandas in a future version. Use pandas.Index with the appropriate dtype instead.
elif isinstance(data.columns, (pd.Int64Index, pd.RangeIndex)):
[17:15:18] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:576:
Parameters: { "silent" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
[17:15:18] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:1115: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
55%|█████▌ | 11/20 [00:03<00:02, 3.40trial/s, best loss: 0.22510822510822515]
/usr/local/lib/python3.9/site-packages/xgboost/sklearn.py:1224: UserWarning: The use of label encoder in XGBClassifier is deprecated and will be removed in a future release. To remove this warning, do the following: 1) Pass option use_label_encoder=False when constructing XGBClassifier object; and 2) Encode your labels (y) as integers starting with 0, i.e. 0, 1, 2, ..., [num_class - 1].
warnings.warn(label_encoder_deprecation_msg, UserWarning)
/usr/local/lib/python3.9/site-packages/xgboost/data.py:262: FutureWarning: pandas.Int64Index is deprecated and will be removed from pandas in a future version. Use pandas.Index with the appropriate dtype instead.
elif isinstance(data.columns, (pd.Int64Index, pd.RangeIndex)):
[17:15:19] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:576:
Parameters: { "silent" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
[17:15:19] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:1115: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
60%|██████ | 12/20 [00:04<00:02, 2.86trial/s, best loss: 0.22510822510822515]
/usr/local/lib/python3.9/site-packages/xgboost/sklearn.py:1224: UserWarning: The use of label encoder in XGBClassifier is deprecated and will be removed in a future release. To remove this warning, do the following: 1) Pass option use_label_encoder=False when constructing XGBClassifier object; and 2) Encode your labels (y) as integers starting with 0, i.e. 0, 1, 2, ..., [num_class - 1].
warnings.warn(label_encoder_deprecation_msg, UserWarning)
/usr/local/lib/python3.9/site-packages/xgboost/data.py:262: FutureWarning: pandas.Int64Index is deprecated and will be removed from pandas in a future version. Use pandas.Index with the appropriate dtype instead.
elif isinstance(data.columns, (pd.Int64Index, pd.RangeIndex)):
[17:15:19] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:576:
Parameters: { "silent" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
[17:15:19] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:1115: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
65%|██████▌ | 13/20 [00:04<00:02, 2.65trial/s, best loss: 0.22510822510822515]
/usr/local/lib/python3.9/site-packages/xgboost/sklearn.py:1224: UserWarning: The use of label encoder in XGBClassifier is deprecated and will be removed in a future release. To remove this warning, do the following: 1) Pass option use_label_encoder=False when constructing XGBClassifier object; and 2) Encode your labels (y) as integers starting with 0, i.e. 0, 1, 2, ..., [num_class - 1].
warnings.warn(label_encoder_deprecation_msg, UserWarning)
/usr/local/lib/python3.9/site-packages/xgboost/data.py:262: FutureWarning: pandas.Int64Index is deprecated and will be removed from pandas in a future version. Use pandas.Index with the appropriate dtype instead.
elif isinstance(data.columns, (pd.Int64Index, pd.RangeIndex)):
[17:15:19] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:576:
Parameters: { "silent" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
[17:15:19] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:1115: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
70%|███████ | 14/20 [00:04<00:01, 3.05trial/s, best loss: 0.22510822510822515]
/usr/local/lib/python3.9/site-packages/xgboost/sklearn.py:1224: UserWarning: The use of label encoder in XGBClassifier is deprecated and will be removed in a future release. To remove this warning, do the following: 1) Pass option use_label_encoder=False when constructing XGBClassifier object; and 2) Encode your labels (y) as integers starting with 0, i.e. 0, 1, 2, ..., [num_class - 1].
warnings.warn(label_encoder_deprecation_msg, UserWarning)
/usr/local/lib/python3.9/site-packages/xgboost/data.py:262: FutureWarning: pandas.Int64Index is deprecated and will be removed from pandas in a future version. Use pandas.Index with the appropriate dtype instead.
elif isinstance(data.columns, (pd.Int64Index, pd.RangeIndex)):
[17:15:20] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:576:
Parameters: { "silent" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
[17:15:20] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:1115: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
75%|███████▌ | 15/20 [00:05<00:01, 3.00trial/s, best loss: 0.22510822510822515]
/usr/local/lib/python3.9/site-packages/xgboost/sklearn.py:1224: UserWarning: The use of label encoder in XGBClassifier is deprecated and will be removed in a future release. To remove this warning, do the following: 1) Pass option use_label_encoder=False when constructing XGBClassifier object; and 2) Encode your labels (y) as integers starting with 0, i.e. 0, 1, 2, ..., [num_class - 1].
warnings.warn(label_encoder_deprecation_msg, UserWarning)
/usr/local/lib/python3.9/site-packages/xgboost/data.py:262: FutureWarning: pandas.Int64Index is deprecated and will be removed from pandas in a future version. Use pandas.Index with the appropriate dtype instead.
elif isinstance(data.columns, (pd.Int64Index, pd.RangeIndex)):
[17:15:20] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:576:
Parameters: { "silent" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
[17:15:20] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:1115: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
85%|████████▌ | 17/20 [00:05<00:00, 3.26trial/s, best loss: 0.22510822510822515]
/usr/local/lib/python3.9/site-packages/xgboost/sklearn.py:1224: UserWarning: The use of label encoder in XGBClassifier is deprecated and will be removed in a future release. To remove this warning, do the following: 1) Pass option use_label_encoder=False when constructing XGBClassifier object; and 2) Encode your labels (y) as integers starting with 0, i.e. 0, 1, 2, ..., [num_class - 1].
warnings.warn(label_encoder_deprecation_msg, UserWarning)
/usr/local/lib/python3.9/site-packages/xgboost/data.py:262: FutureWarning: pandas.Int64Index is deprecated and will be removed from pandas in a future version. Use pandas.Index with the appropriate dtype instead.
elif isinstance(data.columns, (pd.Int64Index, pd.RangeIndex)):
[17:15:20] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:576:
Parameters: { "silent" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
[17:15:20] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:1115: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
[17:15:20] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:576:
Parameters: { "silent" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
[17:15:20] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:1115: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
90%|█████████ | 18/20 [00:06<00:00, 3.91trial/s, best loss: 0.22510822510822515]
/usr/local/lib/python3.9/site-packages/xgboost/sklearn.py:1224: UserWarning: The use of label encoder in XGBClassifier is deprecated and will be removed in a future release. To remove this warning, do the following: 1) Pass option use_label_encoder=False when constructing XGBClassifier object; and 2) Encode your labels (y) as integers starting with 0, i.e. 0, 1, 2, ..., [num_class - 1].
warnings.warn(label_encoder_deprecation_msg, UserWarning)
/usr/local/lib/python3.9/site-packages/xgboost/data.py:262: FutureWarning: pandas.Int64Index is deprecated and will be removed from pandas in a future version. Use pandas.Index with the appropriate dtype instead.
elif isinstance(data.columns, (pd.Int64Index, pd.RangeIndex)):
/usr/local/lib/python3.9/site-packages/xgboost/sklearn.py:1224: UserWarning: The use of label encoder in XGBClassifier is deprecated and will be removed in a future release. To remove this warning, do the following: 1) Pass option use_label_encoder=False when constructing XGBClassifier object; and 2) Encode your labels (y) as integers starting with 0, i.e. 0, 1, 2, ..., [num_class - 1].
warnings.warn(label_encoder_deprecation_msg, UserWarning)
/usr/local/lib/python3.9/site-packages/xgboost/data.py:262: FutureWarning: pandas.Int64Index is deprecated and will be removed from pandas in a future version. Use pandas.Index with the appropriate dtype instead.
elif isinstance(data.columns, (pd.Int64Index, pd.RangeIndex)):
[17:15:21] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:576:
Parameters: { "silent" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
[17:15:21] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:1115: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
95%|█████████▌| 19/20 [00:06<00:00, 3.24trial/s, best loss: 0.22510822510822515]
/usr/local/lib/python3.9/site-packages/xgboost/sklearn.py:1224: UserWarning: The use of label encoder in XGBClassifier is deprecated and will be removed in a future release. To remove this warning, do the following: 1) Pass option use_label_encoder=False when constructing XGBClassifier object; and 2) Encode your labels (y) as integers starting with 0, i.e. 0, 1, 2, ..., [num_class - 1].
warnings.warn(label_encoder_deprecation_msg, UserWarning)
/usr/local/lib/python3.9/site-packages/xgboost/data.py:262: FutureWarning: pandas.Int64Index is deprecated and will be removed from pandas in a future version. Use pandas.Index with the appropriate dtype instead.
elif isinstance(data.columns, (pd.Int64Index, pd.RangeIndex)):
100%|██████████| 20/20 [00:06<00:00, 2.91trial/s, best loss: 0.22510822510822515]
print(best)
best['n_estimators']=int(best['n_estimators'])
best['max_depth']=int(best['max_depth'])
{'colsample_bytree': 0.9500000000000001, 'learning_rate': 0.275, 'max_depth': 11.0, 'n_estimators': 245.0, 'subsample': 0.6000000000000001}
tree_v5 = XGBClassifier(**best)
tree_v5
XGBClassifier(base_score=None, booster=None, colsample_bylevel=None,
colsample_bynode=None, colsample_bytree=0.9500000000000001,
enable_categorical=False, gamma=None, gpu_id=None,
importance_type=None, interaction_constraints=None,
learning_rate=0.275, max_delta_step=None, max_depth=11,
min_child_weight=None, missing=nan, monotone_constraints=None,
n_estimators=245, n_jobs=None, num_parallel_tree=None,
predictor=None, random_state=None, reg_alpha=None,
reg_lambda=None, scale_pos_weight=None,
subsample=0.6000000000000001, tree_method=None,
validate_parameters=None, verbosity=None)
tree_v5.fit(X_train, Y_train)
/usr/local/lib/python3.9/site-packages/xgboost/sklearn.py:1224: UserWarning: The use of label encoder in XGBClassifier is deprecated and will be removed in a future release. To remove this warning, do the following: 1) Pass option use_label_encoder=False when constructing XGBClassifier object; and 2) Encode your labels (y) as integers starting with 0, i.e. 0, 1, 2, ..., [num_class - 1].
warnings.warn(label_encoder_deprecation_msg, UserWarning)
/usr/local/lib/python3.9/site-packages/xgboost/data.py:262: FutureWarning: pandas.Int64Index is deprecated and will be removed from pandas in a future version. Use pandas.Index with the appropriate dtype instead.
elif isinstance(data.columns, (pd.Int64Index, pd.RangeIndex)):
[17:14:44] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:1115: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1,
colsample_bynode=1, colsample_bytree=0.75,
enable_categorical=False, gamma=0, gpu_id=-1,
importance_type=None, interaction_constraints='',
learning_rate=0.375, max_delta_step=0, max_depth=1,
min_child_weight=1, missing=nan, monotone_constraints='()',
n_estimators=655, n_jobs=8, num_parallel_tree=1, predictor='auto',
random_state=0, reg_alpha=0, reg_lambda=1, scale_pos_weight=1,
subsample=1.0, tree_method='exact', validate_parameters=1,
verbosity=None)
# métricas de desempeño
# accuracy
print('accuracy del clasificador - version 5 : {0:.2f}'.format(accuracy_score(Y_test, tree_v5.predict(X_test))))
# confusion matrix
print('matriz de confusión del clasificador - version 5: \n {0}'.format(confusion_matrix(Y_test, tree_v5.predict(X_test))))
# precision
print('precision del clasificador - version 5 : {0:.2f}'.format(precision_score(Y_test, tree_v5.predict(X_test))))
# precision
print('recall del clasificador - version 5 : {0:.2f}'.format(recall_score(Y_test, tree_v5.predict(X_test))))
# f1
print('f1 del clasificador - version 5 : {0:.2f}'.format(f1_score(Y_test, tree_v5.predict(X_test))))
accuracy del clasificador - version 5 : 0.81
matriz de confusión del clasificador - version 5:
[[128 18]
[ 26 59]]
precision del clasificador - version 5 : 0.77
recall del clasificador - version 5 : 0.69
f1 del clasificador - version 5 : 0.73
/usr/local/lib/python3.9/site-packages/xgboost/data.py:262: FutureWarning: pandas.Int64Index is deprecated and will be removed from pandas in a future version. Use pandas.Index with the appropriate dtype instead.
elif isinstance(data.columns, (pd.Int64Index, pd.RangeIndex)):
/usr/local/lib/python3.9/site-packages/xgboost/data.py:262: FutureWarning: pandas.Int64Index is deprecated and will be removed from pandas in a future version. Use pandas.Index with the appropriate dtype instead.
elif isinstance(data.columns, (pd.Int64Index, pd.RangeIndex)):
/usr/local/lib/python3.9/site-packages/xgboost/data.py:262: FutureWarning: pandas.Int64Index is deprecated and will be removed from pandas in a future version. Use pandas.Index with the appropriate dtype instead.
elif isinstance(data.columns, (pd.Int64Index, pd.RangeIndex)):
/usr/local/lib/python3.9/site-packages/xgboost/data.py:262: FutureWarning: pandas.Int64Index is deprecated and will be removed from pandas in a future version. Use pandas.Index with the appropriate dtype instead.
elif isinstance(data.columns, (pd.Int64Index, pd.RangeIndex)):
/usr/local/lib/python3.9/site-packages/xgboost/data.py:262: FutureWarning: pandas.Int64Index is deprecated and will be removed from pandas in a future version. Use pandas.Index with the appropriate dtype instead.
elif isinstance(data.columns, (pd.Int64Index, pd.RangeIndex)):
Guardar el clasificador¶
Python cuenta con librerias de serialización que facilitan guardar el clasificador en un archivo (pickle, joblib); este archivo puede ser restaurado para hacer predicciones.
import pickle
# Cree la carpeta 'clasificador' en el folder donde está el notebook
ruta_archivo_clasificador = os.path.join('tree_v5.pkl')
# Abrir el archivo para escribir contenido binario
archivo_clasificador = open(ruta_archivo_clasificador, 'wb')
# Guardar el clasificador
pickle.dump(tree_v5, archivo_clasificador)
# Cerrar el archivo
archivo_clasificador.close()
Cargar el clasificador¶
#Abrir el archivo en modo lectura de contenido binario y cargar el clasificdor
archivo_clasificador = open(ruta_archivo_clasificador, "rb")
tree_v6 = pickle.load(archivo_clasificador)
archivo_clasificador.close()
# métricas de desempeño
# accuracy
print('accuracy del clasificador - version 6 : {0:.2f}'.format(accuracy_score(Y_test, tree_v6.predict(X_test))))
# confusion matrix
print('matriz de confusión del clasificador - version 6: \n {0}'.format(confusion_matrix(Y_test, tree_v6.predict(X_test))))
# precision
print('precision del clasificador - version 6 : {0:.2f}'.format(precision_score(Y_test, tree_v6.predict(X_test))))
# precision
print('recall del clasificador - version 6 : {0:.2f}'.format(recall_score(Y_test, tree_v6.predict(X_test))))
# f1
print('f1 del clasificador - version 6 : {0:.2f}'.format(f1_score(Y_test, tree_v6.predict(X_test))))
accuracy del clasificador - version 6 : 0.79
matriz de confusión del clasificador - version 6:
[[126 20]
[ 29 56]]
precision del clasificador - version 6 : 0.74
recall del clasificador - version 6 : 0.66
f1 del clasificador - version 6 : 0.70
Modificar el clasificador¶
tree_v6.n_estimators = 700
# Volver a entrenar el clasificador con los nuevos parámetros
tree_v6.fit(X_train,Y_train)
XGBClassifier(base_score=0.5, booster=None, colsample_bylevel=1,
colsample_bynode=1, colsample_bytree=0.9, gamma=0, gpu_id=-1,
importance_type='gain', interaction_constraints=None,
learning_rate=0.025, max_delta_step=0, max_depth=4,
min_child_weight=1, missing=nan, monotone_constraints=None,
n_estimators=700, n_jobs=0, num_parallel_tree=1,
objective='binary:logistic', random_state=0, reg_alpha=0,
reg_lambda=1, scale_pos_weight=1, subsample=0.6000000000000001,
tree_method=None, validate_parameters=False, verbosity=None)
# Guardar el nuevo clasificador
ruta_archivo_clasificador = os.path.join('tree_v6.pkl')
archivo_clasificador = open(ruta_archivo_clasificador, "wb")
pickle.dump(tree_v6, archivo_clasificador)
archivo_clasificador.close()
Opciones de despliegue¶
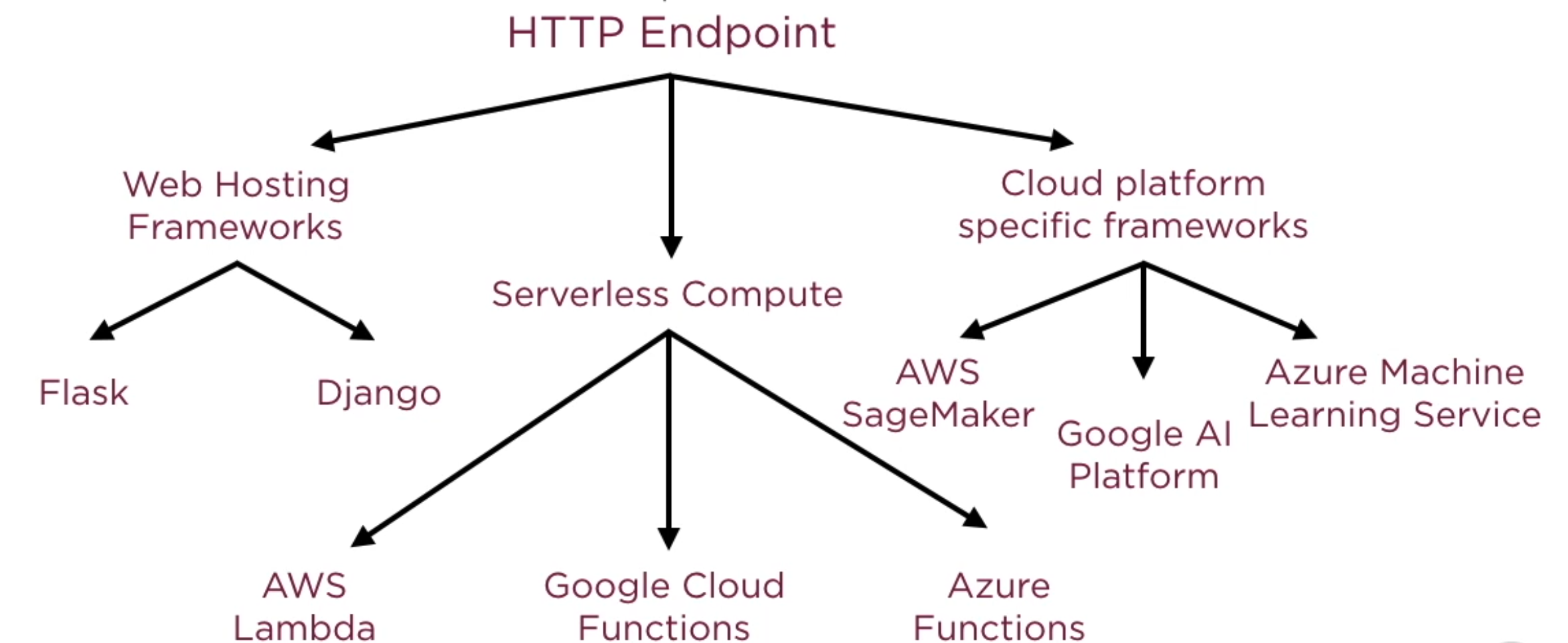
Flask¶
Flask es un framework minimalista escrito en Python que permite crear aplicaciones web rápidamente y con un mínimo número de líneas de código - Wikipedia.
Ahora, utilizando el clasificador guardado anteriormente en un archivo binario, se creará un servicio API REST en Flask para poder utilizarlo. Para hacerlo funcionar hacerlo, colocar el código en un archivo .py y hacerlo correr en la consola.
# http://flask.palletsprojects.com/en/1.1.x/quickstart/#quickstart
from flask import Flask, request, jsonify
import os
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import pickle
app = Flask(__name__)
classifier_filepath = os.path.join("tree_v6.pkl")
classifier_file = open(classifier_filepath, "rb")
classifier = pickle.load(open(classifier_filepath, "rb"))
classifier_file.close()
# Desactiva el API /predict del clasificador.
# retorna {"message": "/predict disabled"}, 200 OK
@app.route('/disable', methods=['GET'])
def disable():
global ACTIVATED
ACTIVATED = False
return {'message': '/predict disabled'}, 200
# Activa el API /predict del clasificador.
# retorna {"message": "/predict enabled"}, 200 OK
@app.route('/enable', methods=['GET'])
def enable():
global ACTIVATED
ACTIVATED = True
return {'message': '/predict enabled'}, 200
# Entrena el modelo con los nuevos hyper-parámetros y retorna la nueva exactitud. Por ejemplo, {"accuracy": 0.81}, 200 OK
# Se pueden enviar los siguiente hyper-parámetros: { "n_estimators": 10, "criterion": "gini", "max_depth": 7 }
# "criterion" puede ser "gini" o "entropy", "n_estimators" y "max_depth" son un número entero positivo
# Unicamente "max_depth" es opcional en cuyo caso se deberá emplear None. Si los otros hyper-parámetros no están presentes se retorna:
# {"message": "missing hyper-parameter"}, 404 BAD REQUEST
# Finalmente, sólo se puede ejecutar este endpoint después de ejecutar GET /disable. En otro caso retorna {"message": "can not reset an enabled classifier"}, 400 BAD REQUEST
@app.route('/reset', methods=['POST'])
def reset():
if ACTIVATED:
return {"message": "can not reset an enabled classifier"}, 400
json_request = request.get_json(force=True)
if 'criterion' not in json_request or 'n_estimators' not in json_request:
return {"message": "missing hyper-parameter"}, 400
classifier.n_estimators = json_request.get('n_estimators')
classifier.criterion = json_request.get('criterion')
classifier.max_depth = json_request.get('max_depth')
df = pd.read_csv(os.path.join("diabetes.csv"))
feature_cols = ['Pregnancies', 'Insulin', 'BMI', 'Age',
'Glucose', 'BloodPressure', 'DiabetesPedigreeFunction']
X = df[feature_cols]
Y = df["Outcome"]
X_train, X_test, Y_train, Y_test = train_test_split(
X, Y, test_size=0.3, random_state=1)
classifier.fit(X_train, Y_train)
return {'accuracy': accuracy_score(Y_test, classifier.predict(X_test))}, 200
# Recibe una lista de observaciones y retorna la clasificación para cada una de ellas.
# Los valores en cada observación se corresponden con la siguientes variables:
#['Pregnancies', 'Insulin', 'BMI', 'Age', 'Glucose', 'BloodPressure', 'DiabetesPedigreeFunction']
# Por ejemplo: para estas observaciones:
# [
# [7,135,26.0,51,136,74,0.647],
# [9,175,34.2,36,112,82,0.260]
# ]
@app.route('/predict', methods=['POST'])
def predict():
if not ACTIVATED:
return {"message": "classifier is not enabled"}, 400
predict_request = request.get_json(force=True)
predict_response = classifier.predict(predict_request)
return {'cases': predict_request,
'diabetes': predict_response.tolist()}
if __name__ == '__main__':
app.run(port=8080, debug=True)